Reading waterinfo observations
This notebook introduces how to use the hydropandas package to read, process and visualise data from the Waterinfo database. In this notebook the ddlpy package (https://github.com/Deltares/ddlpy) is used to access the waterinfo api. This package can be installed using pip install rws-ddlpy.
[1]:
import contextily as ctx
import pandas as pd
import hydropandas as hpd
from hydropandas.io.waterinfo import get_locations_gdf
# enabling debug logging so we can see what happens in the background
hpd.util.get_color_logger("INFO");
[2]:
# settings
grootheid_code = None
locatie = "schoonhoven"
proces_type = "meting"
tmin = pd.Timestamp("2020-1-1")
tmax = pd.Timestamp("2020-1-3")
extent = (110000, 125000, 429550, 449900) # Schoonhoven
[3]:
# get waterinfo observations within an extent
oc = hpd.read_waterinfo(
extent=extent,
grootheid_code=grootheid_code,
proces_type=proces_type,
locatie=locatie,
tmin=tmin,
tmax=tmax,
keep_all_obs=False,
)
oc
INFO:ddlpy.ddlpy.retrieve_or_load_catalog:Retrieving Waterwebservices catalog, this can take 30 seconds
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
Cell In[3], line 2
1 # get waterinfo observations within an extent
----> 2 oc = hpd.read_waterinfo(
3 extent=extent,
4 grootheid_code=grootheid_code,
5 proces_type=proces_type,
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/obs_collection.py:1138, in read_waterinfo(file_or_dir, extent, name, ObsClass, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax, only_metadata, keep_all_obs, epsg, progressbar, location_gdf, **kwargs)
1072 def read_waterinfo(
1073 file_or_dir=None,
1074 extent=None,
(...) 1089 **kwargs,
1090 ):
1091 """Read waterinfo measurement within an extent or from a file or directory
1092
1093 Parameters
(...) 1135 ObsCollection containing data
1136 """
-> 1138 oc = ObsCollection.from_waterinfo(
1139 extent=extent,
1140 file_or_dir=file_or_dir,
1141 name=name,
1142 ObsClass=ObsClass,
1143 locatie=locatie,
1144 grootheid_code=grootheid_code,
1145 groepering_code=groepering_code,
1146 parameter_code=parameter_code,
1147 proces_type=proces_type,
1148 tmin=tmin,
1149 tmax=tmax,
1150 only_metadata=only_metadata,
1151 keep_all_obs=keep_all_obs,
1152 epsg=epsg,
1153 progressbar=progressbar,
1154 location_gdf=location_gdf,
1155 **kwargs,
1156 )
1158 return oc
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/obs_collection.py:2840, in ObsCollection.from_waterinfo(cls, file_or_dir, extent, name, ObsClass, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax, only_metadata, keep_all_obs, epsg, progressbar, location_gdf, **kwargs)
2837 meta = {"name": name, "type": ObsClass}
2839 if (extent is not None) or (location_gdf is not None):
-> 2840 obs_list = waterinfo.get_obs_list_from_extent(
2841 extent,
2842 ObsClass,
2843 locatie=locatie,
2844 grootheid_code=grootheid_code,
2845 groepering_code=groepering_code,
2846 parameter_code=parameter_code,
2847 proces_type=proces_type,
2848 tmin=tmin,
2849 tmax=tmax,
2850 only_metadata=only_metadata,
2851 keep_all_obs=keep_all_obs,
2852 epsg=epsg,
2853 location_gdf=location_gdf,
2854 )
2855 elif file_or_dir is not None:
2856 obs_list = waterinfo.read_waterinfo_obs(
2857 file_or_dir, ObsClass, progressbar=progressbar, **kwargs
2858 )
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/io/waterinfo.py:73, in get_obs_list_from_extent(extent, ObsClass, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax, only_metadata, keep_all_obs, epsg, location_gdf)
30 """Get observations within a specific extent and optionally for a specific location
31 and grootheid_code.
32
(...) 70
71 """
72 if location_gdf is None:
---> 73 gdf = get_locations_gdf(epsg=epsg)
74 gdf = get_locations_within_extent(gdf, extent=extent)
75 else:
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/io/waterinfo.py:389, in get_locations_gdf(epsg)
378 """Get locations from ddlpy and return as geodataframe
379
380 Returns
(...) 384 using ddlpy
385 """
387 import ddlpy
--> 389 locations = ddlpy.locations()
390 geometries = gpd.points_from_xy(locations["Lon"], locations["Lat"])
391 gdf = gpd.GeoDataFrame(locations, geometry=geometries, crs=4326)
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/ddlpy/ddlpy.py:120, in locations(catalog_filter)
99 def locations(catalog_filter: list = None) -> pd.DataFrame:
100 """
101 Get station information from DDL (metadata from Catalogue). It conains all metadata
102 regarding stations. The catalog is locally cached for maximum 4 hours, corresponding
(...) 117
118 """
--> 120 result = retrieve_or_load_catalog(catalog_filter=catalog_filter)
122 df_locations = pd.DataFrame(result["LocatieLijst"])
124 df_metadata = pd.json_normalize(result["AquoMetadataLijst"])
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/ddlpy/ddlpy.py:91, in retrieve_or_load_catalog(catalog_filter)
89 else:
90 logger.info("Retrieving Waterwebservices catalog, this can take 30 seconds")
---> 91 result = catalog(catalog_filter=catalog_filter)
92 if catalog_filter is None:
93 # only write the catalogfile if the default catalog_filter was used
94 with open(catalogfile, "w") as f:
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/ddlpy/ddlpy.py:58, in catalog(catalog_filter)
55 assert isinstance(catalog_filter, list)
56 request = {"CatalogusFilter": {x: True for x in catalog_filter}}
---> 58 result = _send_post_request(endpoint["url"], request, timeout=None)
60 return result
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/ddlpy/ddlpy.py:38, in _send_post_request(url, request, timeout)
32 resp = requests.post(url, json=request, timeout=timeout)
34 if not resp.ok:
35 # in case of for instance
36 # resp.status_code: 400, resp.reason: Bad Request, resp.text: {"Succesvol":false,"Foutmelding":"Het maximaal aantal waarnemingen (160000) is overschreden. Beperk uw request.","WaarnemingenLijst":[]}
37 # resp.status_code: 500, resp.reason: Internal Server Error
---> 38 raise IOError(f"{resp.status_code} {resp.reason}: {resp.text}")
40 if resp.status_code == 204:
41 # "204 No Content" is raised here, but catched in ddlpy.ddlpy.measurements() so the process can continue.
42 raise NoDataError(f"{resp.status_code} {resp.reason}: {resp.text}")
OSError: 504 Gateway Timeout: Gateway Timeout
[4]:
# show all measurement types within the extent
gdf_meas = get_locations_gdf()
gdf_meas.loc[
locatie,
[
"Grootheid.Code",
"Grootheid.Omschrijving",
"Groepering.Code",
"Groepering.Omschrijving",
"Parameter.Code",
"Parameter.Omschrijving",
"ProcesType",
],
]
INFO:ddlpy.ddlpy.retrieve_or_load_catalog:Retrieving Waterwebservices catalog, this can take 30 seconds
[4]:
| Grootheid.Code | Grootheid.Omschrijving | Groepering.Code | Groepering.Omschrijving | Parameter.Code | Parameter.Omschrijving | ProcesType | |
|---|---|---|---|---|---|---|---|
| Code | |||||||
| schoonhoven | 50%_L | 50 percentiel van de levendigheid | LEVDHD5 | Levendigheid | NVT | NVT | meting |
| schoonhoven | 70%_L | 70 percentiel van de levendigheid | LEVDHD5 | Levendigheid | NVT | NVT | meting |
| schoonhoven | 80%_L | 80 percentiel van de levendigheid | LEVDHD5 | Levendigheid | NVT | NVT | meting |
| schoonhoven | 90%_L | 90 percentiel van de levendigheid | LEVDHD5 | Levendigheid | NVT | NVT | meting |
| schoonhoven | HOOGWTDG | Hoogwater dag | NVT | NVT | meting | ||
| schoonhoven | HOOGWTNT | Hoogwater nacht | NVT | NVT | meting | ||
| schoonhoven | LAAGWTDG | Laagwater dag | NVT | NVT | meting | ||
| schoonhoven | NVT | NVT | NVT | NVT | meting | ||
| schoonhoven | NVT | NVT | LEVDHD5 | Levendigheid | NVT | NVT | meting |
| schoonhoven | NVT | NVT | GETETBRKD2 | Getijextreem berekend | NVT | NVT | astronomisch |
| schoonhoven | NVT | NVT | GETETM2 | Getijextremen | NVT | NVT | meting |
| schoonhoven | NVT | NVT | NVT | NVT | meting | ||
| schoonhoven | WATHTE | Waterhoogte | NVT | NVT | astronomisch | ||
| schoonhoven | WATHTE | Waterhoogte | NVT | NVT | verwachting | ||
| schoonhoven | WATHTE | Waterhoogte | NVT | NVT | meting | ||
| schoonhoven | WATHTE | Waterhoogte | GETETBRKD2 | Getijextreem berekend | NVT | NVT | astronomisch |
| schoonhoven | WATHTE | Waterhoogte | GETETM2 | Getijextremen | NVT | NVT | meting |
[5]:
# get data from a certain location and grootheid
o1 = hpd.WaterlvlObs.from_waterinfo(
locatie="schoonhoven",
grootheid_code="WATHTE",
groepering_code="",
proces_type="meting",
tmin=tmin,
tmax=tmax,
location_gdf=gdf_meas, # specifying the location_gdf signficantly speeds up the process
)
o1
100%|██████████| 1/1 [00:00<00:00, 1.33it/s]
[5]:
hydropandas.WaterlvlObs
| Schoonhoven Waterhoogte | |
|---|---|
| x | 118061.727238 |
| y | 439419.244069 |
| location | Schoonhoven |
| filename | |
| source | waterinfo (ddlpy) |
| unit | cm NAP |
| metadata_available | NaN |
| value | |
|---|---|
| time | |
| 2020-01-01 01:00:00 | 52.0 |
| 2020-01-01 01:10:00 | 49.0 |
| 2020-01-01 01:20:00 | 47.0 |
| 2020-01-01 01:30:00 | 44.0 |
| 2020-01-01 01:40:00 | 42.0 |
| ... | ... |
| 2020-01-03 00:20:00 | 90.0 |
| 2020-01-03 00:30:00 | 88.0 |
| 2020-01-03 00:40:00 | 85.0 |
| 2020-01-03 00:50:00 | 83.0 |
| 2020-01-03 01:00:00 | 81.0 |
289 rows × 1 columns
[6]:
# get data from a certain location and grootheid
o2 = hpd.WaterlvlObs.from_waterinfo(
locatie="schoonhoven",
grootheid_code="WATHTE",
groepering_code="",
proces_type="astronomisch",
tmin=tmin,
tmax=tmax,
location_gdf=gdf_meas, # specifying the location_gdf signficantly speeds up the process
)
# plot data
ax = o1["value"].plot(ylabel=o1.unit, label=o1.name, legend=True)
o2["value"].plot(ylabel=o2.unit, label=o2.name, marker="o", legend=True, ax=ax);
0%| | 0/1 [00:30<?, ?it/s]
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
Cell In[6], line 2
1 # get data from a certain location and grootheid
----> 2 o2 = hpd.WaterlvlObs.from_waterinfo(
3 locatie="schoonhoven",
4 grootheid_code="WATHTE",
5 groepering_code="",
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/observation.py:1531, in WaterlvlObs.from_waterinfo(cls, path, location_gdf, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax, **kwargs)
1496 """Read data from waterinfo csv-file, zip or using the API.
1497
1498 Parameters
(...) 1527 if file contains data for more than one location
1528 """
1529 from .io import waterinfo
-> 1531 df, metadata = waterinfo.get_waterinfo_obs(
1532 path=path,
1533 location_gdf=location_gdf,
1534 locatie=locatie,
1535 grootheid_code=grootheid_code,
1536 groepering_code=groepering_code,
1537 parameter_code=parameter_code,
1538 proces_type=proces_type,
1539 tmin=tmin,
1540 tmax=tmax,
1541 **kwargs,
1542 )
1544 return cls(df, **metadata)
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/io/waterinfo.py:163, in get_waterinfo_obs(path, location_gdf, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax, **kwargs)
161 df, meta = read_waterinfo_file(path, **kwargs)
162 else:
--> 163 df, meta = get_measurements_ddlpy(
164 location_gdf,
165 locatie,
166 grootheid_code,
167 groepering_code,
168 parameter_code,
169 proces_type,
170 tmin,
171 tmax,
172 )
174 return df, meta
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/io/waterinfo.py:342, in get_measurements_ddlpy(location_gdf, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax)
340 if len(selected) == 1:
341 selected = selected.iloc[0]
--> 342 df = ddlpy.measurements(selected, start_date=tmin, end_date=tmax)
343 else:
344 logger.info(
345 "Multiple observation points match critera, select first one with measurements"
346 )
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/ddlpy/ddlpy.py:467, in measurements(location, start_date, end_date, freq, clean_df)
465 for start_date_i, end_date_i in date_series_iterator:
466 try:
--> 467 measurement = _measurements_slice(
468 location, start_date=start_date_i, end_date=end_date_i
469 )
470 measurements.append(measurement)
471 except NoDataError:
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/ddlpy/ddlpy.py:394, in _measurements_slice(location, start_date, end_date)
386 request_dicts = _get_request_dicts(location)
388 request = {
389 "AquoPlusWaarnemingMetadata": {"AquoMetadata": request_dicts["AquoMetadata"]},
390 "Locatie": request_dicts["Locatie"],
391 "Periode": {"Begindatumtijd": start_date_str, "Einddatumtijd": end_date_str},
392 }
--> 394 result = _send_post_request(endpoint["url"], request, timeout=None)
396 df = _combine_waarnemingenlijst(result, location)
397 return df
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/ddlpy/ddlpy.py:38, in _send_post_request(url, request, timeout)
32 resp = requests.post(url, json=request, timeout=timeout)
34 if not resp.ok:
35 # in case of for instance
36 # resp.status_code: 400, resp.reason: Bad Request, resp.text: {"Succesvol":false,"Foutmelding":"Het maximaal aantal waarnemingen (160000) is overschreden. Beperk uw request.","WaarnemingenLijst":[]}
37 # resp.status_code: 500, resp.reason: Internal Server Error
---> 38 raise IOError(f"{resp.status_code} {resp.reason}: {resp.text}")
40 if resp.status_code == 204:
41 # "204 No Content" is raised here, but catched in ddlpy.ddlpy.measurements() so the process can continue.
42 raise NoDataError(f"{resp.status_code} {resp.reason}: {resp.text}")
OSError: 504 Gateway Timeout: Gateway Timeout
[7]:
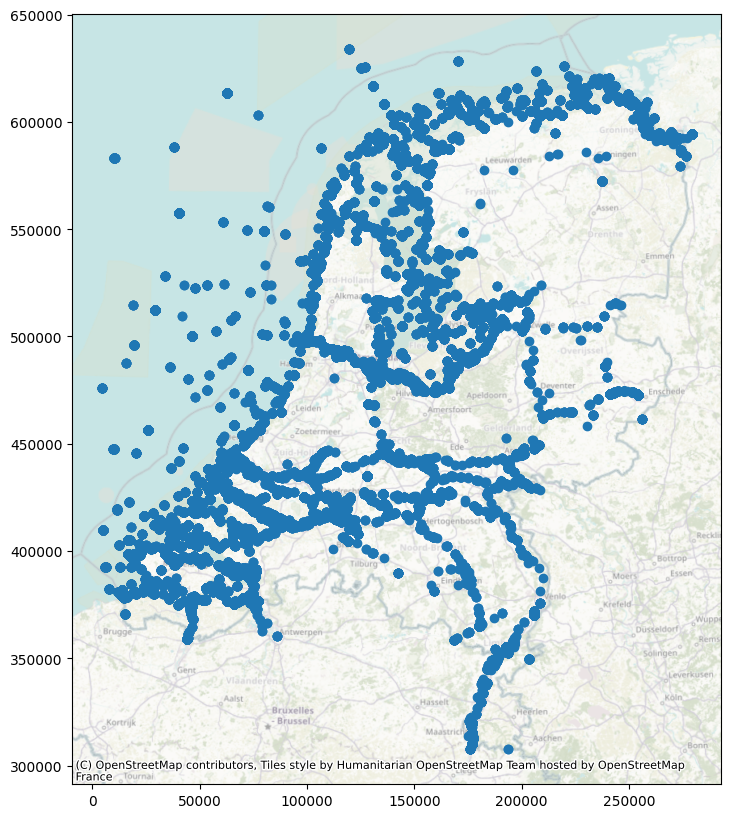
# get all measurement points within the Netherlands
gdf = hpd.io.waterinfo.get_locations_gdf()
gdf = hpd.io.waterinfo.get_locations_within_extent(
gdf, extent=(482.06, 306602.42, 284182.97, 637049.52)
)
ax = gdf.plot(figsize=(10, 10))
ctx.add_basemap(ax=ax, crs=28992, alpha=0.5)
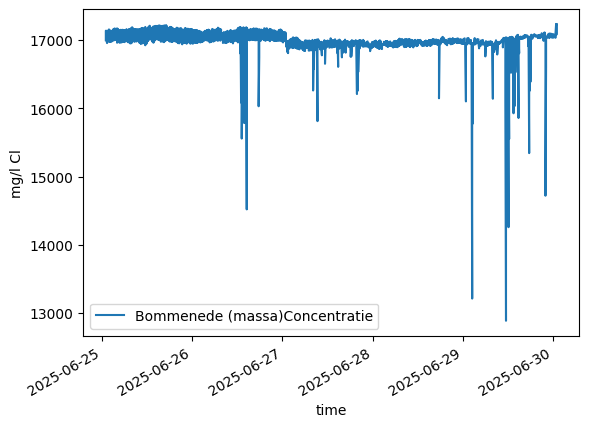
Water quality data
The Waterinfo database also contains water quality data
[8]:
# get chloride concentration from the Oosterschelde (Bommenede 1 (b))
o_cl = hpd.WaterlvlObs.from_waterinfo(
locatie="bommenede",
parameter_code="Cl",
tmin="2025-6-25",
tmax="2025-6-30",
location_gdf=gdf,
)
# plot data
ax = o_cl["value"].plot(ylabel=o_cl.unit, label=o_cl.name, legend=True)
INFO:hydropandas.io.waterinfo.get_measurements_ddlpy:Multiple observation points match critera, select first one with measurements
100%|██████████| 1/1 [00:01<00:00, 1.11s/it]
Or download all chloride measurements within a certain extent
[9]:
oc = hpd.read_waterinfo(
extent=(80000, 90000, 429550, 449900),
parameter_code="Cl",
tmin="2025-6-1",
tmax="2025-6-10",
)
oc.plots.interactive_map(popup_width=350)
INFO:ddlpy.ddlpy.retrieve_or_load_catalog:Loading Waterwebservices catalog from cache
INFO:hydropandas.io.waterinfo.get_obs_list_from_extent:downloading waterinfo measurements from 8 observation points
100%|██████████| 1/1 [00:01<00:00, 1.84s/it]
100%|██████████| 1/1 [00:01<00:00, 1.83s/it]
0%| | 0/1 [00:30<?, ?it/s]
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
Cell In[9], line 1
----> 1 oc = hpd.read_waterinfo(
2 extent=(80000, 90000, 429550, 449900),
3 parameter_code="Cl",
4 tmin="2025-6-1",
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/obs_collection.py:1138, in read_waterinfo(file_or_dir, extent, name, ObsClass, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax, only_metadata, keep_all_obs, epsg, progressbar, location_gdf, **kwargs)
1072 def read_waterinfo(
1073 file_or_dir=None,
1074 extent=None,
(...) 1089 **kwargs,
1090 ):
1091 """Read waterinfo measurement within an extent or from a file or directory
1092
1093 Parameters
(...) 1135 ObsCollection containing data
1136 """
-> 1138 oc = ObsCollection.from_waterinfo(
1139 extent=extent,
1140 file_or_dir=file_or_dir,
1141 name=name,
1142 ObsClass=ObsClass,
1143 locatie=locatie,
1144 grootheid_code=grootheid_code,
1145 groepering_code=groepering_code,
1146 parameter_code=parameter_code,
1147 proces_type=proces_type,
1148 tmin=tmin,
1149 tmax=tmax,
1150 only_metadata=only_metadata,
1151 keep_all_obs=keep_all_obs,
1152 epsg=epsg,
1153 progressbar=progressbar,
1154 location_gdf=location_gdf,
1155 **kwargs,
1156 )
1158 return oc
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/obs_collection.py:2840, in ObsCollection.from_waterinfo(cls, file_or_dir, extent, name, ObsClass, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax, only_metadata, keep_all_obs, epsg, progressbar, location_gdf, **kwargs)
2837 meta = {"name": name, "type": ObsClass}
2839 if (extent is not None) or (location_gdf is not None):
-> 2840 obs_list = waterinfo.get_obs_list_from_extent(
2841 extent,
2842 ObsClass,
2843 locatie=locatie,
2844 grootheid_code=grootheid_code,
2845 groepering_code=groepering_code,
2846 parameter_code=parameter_code,
2847 proces_type=proces_type,
2848 tmin=tmin,
2849 tmax=tmax,
2850 only_metadata=only_metadata,
2851 keep_all_obs=keep_all_obs,
2852 epsg=epsg,
2853 location_gdf=location_gdf,
2854 )
2855 elif file_or_dir is not None:
2856 obs_list = waterinfo.read_waterinfo_obs(
2857 file_or_dir, ObsClass, progressbar=progressbar, **kwargs
2858 )
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/io/waterinfo.py:100, in get_obs_list_from_extent(extent, ObsClass, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax, only_metadata, keep_all_obs, epsg, location_gdf)
98 o = ObsClass(meta=meta, **meta)
99 else:
--> 100 o = ObsClass.from_waterinfo(location_gdf=row, tmin=tmin, tmax=tmax)
101 if not keep_all_obs and o.empty:
102 continue
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/observation.py:1531, in WaterlvlObs.from_waterinfo(cls, path, location_gdf, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax, **kwargs)
1496 """Read data from waterinfo csv-file, zip or using the API.
1497
1498 Parameters
(...) 1527 if file contains data for more than one location
1528 """
1529 from .io import waterinfo
-> 1531 df, metadata = waterinfo.get_waterinfo_obs(
1532 path=path,
1533 location_gdf=location_gdf,
1534 locatie=locatie,
1535 grootheid_code=grootheid_code,
1536 groepering_code=groepering_code,
1537 parameter_code=parameter_code,
1538 proces_type=proces_type,
1539 tmin=tmin,
1540 tmax=tmax,
1541 **kwargs,
1542 )
1544 return cls(df, **metadata)
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/io/waterinfo.py:163, in get_waterinfo_obs(path, location_gdf, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax, **kwargs)
161 df, meta = read_waterinfo_file(path, **kwargs)
162 else:
--> 163 df, meta = get_measurements_ddlpy(
164 location_gdf,
165 locatie,
166 grootheid_code,
167 groepering_code,
168 parameter_code,
169 proces_type,
170 tmin,
171 tmax,
172 )
174 return df, meta
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/io/waterinfo.py:329, in get_measurements_ddlpy(location_gdf, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax)
327 parameter_code = selected["Parameter.Code"]
328 proces_type = selected["ProcesType"]
--> 329 df = ddlpy.measurements(selected, start_date=tmin, end_date=tmax)
330 else:
331 selected = _select_location(
332 location_gdf,
333 locatie,
(...) 337 proces_type,
338 )
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/ddlpy/ddlpy.py:467, in measurements(location, start_date, end_date, freq, clean_df)
465 for start_date_i, end_date_i in date_series_iterator:
466 try:
--> 467 measurement = _measurements_slice(
468 location, start_date=start_date_i, end_date=end_date_i
469 )
470 measurements.append(measurement)
471 except NoDataError:
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/ddlpy/ddlpy.py:394, in _measurements_slice(location, start_date, end_date)
386 request_dicts = _get_request_dicts(location)
388 request = {
389 "AquoPlusWaarnemingMetadata": {"AquoMetadata": request_dicts["AquoMetadata"]},
390 "Locatie": request_dicts["Locatie"],
391 "Periode": {"Begindatumtijd": start_date_str, "Einddatumtijd": end_date_str},
392 }
--> 394 result = _send_post_request(endpoint["url"], request, timeout=None)
396 df = _combine_waarnemingenlijst(result, location)
397 return df
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/ddlpy/ddlpy.py:38, in _send_post_request(url, request, timeout)
32 resp = requests.post(url, json=request, timeout=timeout)
34 if not resp.ok:
35 # in case of for instance
36 # resp.status_code: 400, resp.reason: Bad Request, resp.text: {"Succesvol":false,"Foutmelding":"Het maximaal aantal waarnemingen (160000) is overschreden. Beperk uw request.","WaarnemingenLijst":[]}
37 # resp.status_code: 500, resp.reason: Internal Server Error
---> 38 raise IOError(f"{resp.status_code} {resp.reason}: {resp.text}")
40 if resp.status_code == 204:
41 # "204 No Content" is raised here, but catched in ddlpy.ddlpy.measurements() so the process can continue.
42 raise NoDataError(f"{resp.status_code} {resp.reason}: {resp.text}")
OSError: 504 Gateway Timeout: Gateway Timeout
Find selection criteria
Very often you don’t know exactly the names of the location, grootheid_code, groepering_code or parameter_code. To get the data that you want you can follow these steps:
get a geodataframe with all the locations in the extent
query the geodataframe to find either a location/grootheid_code/groepering_code or parameter_code
call
read_waterinfowith your selection criteria and a tmin and tmax value
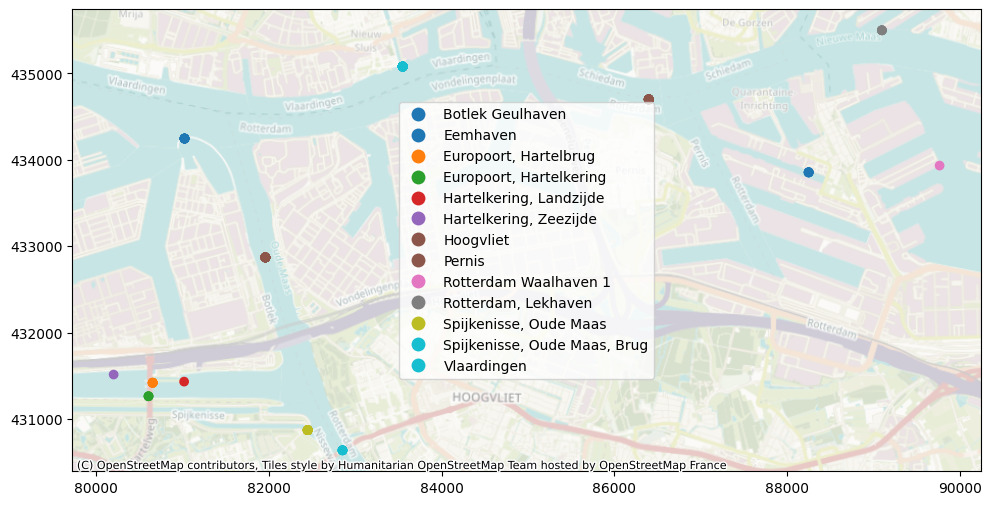
[10]:
# 1 download geodataframe with all measurement points in your extent
gdf = hpd.io.waterinfo.get_locations_gdf()
gdf_locatie = hpd.io.waterinfo.get_locations_within_extent(
gdf, extent=(80000, 90000, 429550, 449900)
)
[11]:
# 2 query the GeoDataFrame
# print unique names
print(f"Unique values of Grootheid Code: \n{gdf_locatie['Grootheid.Code'].unique()}\n")
print(
f"Unique values of Groepering Code: \n{gdf_locatie['Groepering.Code'].unique()}\n"
)
print(f"Unique values of Parameter Code: \n{gdf_locatie['Parameter.Code'].unique()}\n")
print(f"Unique values of Proces Type: \n{gdf_locatie['ProcesType'].unique()}\n")
# plot locations
ax = gdf_locatie.plot("Naam", figsize=(16, 6), legend=True)
ctx.add_basemap(ax=ax, crs=28992, alpha=0.5)
Unique values of Grootheid Code:
['50%_L' '70%_L' '80%_L' '90%_L' 'CONCTTE' 'GELDHD' 'HOOGWTDG' 'HOOGWTNT'
'LAAGWTDG' 'MASSFTE' 'NVT' 'pH' 'PMV' 'SALNTT' 'STROOMSHD' 'T' 'VERZDGGD'
'VOLMFTE' 'WATHTE' 'WATOZT' 'WINDRTG' 'WINDSHD' 'ZICHT']
Unique values of Groepering Code:
['LEVDHD5' '' 'GETETBRKD2' 'GETETM2' 'GETETOZBRKD2']
Unique values of Parameter Code:
['NVT' 'GR' 'Cl' 'NKj' 'SO4' 'NH4' 'NO2' 'sNO3NO2' 'BZV5a' 'F' 'O2' 'OS'
'sMBAS' 'TOC' 'Ptot' 'sPO4' 'PO4' 'SiO2' 'CHLFa' 'FolINDX' 'minrlole']
Unique values of Proces Type:
['meting' 'astronomisch' 'verwachting']
[12]:
# 3 read data for selection criteria
oc = hpd.read_waterinfo(
parameter_code="Cl", tmin="2025-6-1", tmax="2025-6-10", location_gdf=gdf_locatie
)
oc
INFO:hydropandas.io.waterinfo.get_obs_list_from_extent:downloading waterinfo measurements from 8 observation points
0%| | 0/1 [00:30<?, ?it/s]
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
Cell In[12], line 2
1 # 3 read data for selection criteria
----> 2 oc = hpd.read_waterinfo(
3 parameter_code="Cl", tmin="2025-6-1", tmax="2025-6-10", location_gdf=gdf_locatie
4 )
5 oc
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/obs_collection.py:1138, in read_waterinfo(file_or_dir, extent, name, ObsClass, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax, only_metadata, keep_all_obs, epsg, progressbar, location_gdf, **kwargs)
1072 def read_waterinfo(
1073 file_or_dir=None,
1074 extent=None,
(...) 1089 **kwargs,
1090 ):
1091 """Read waterinfo measurement within an extent or from a file or directory
1092
1093 Parameters
(...) 1135 ObsCollection containing data
1136 """
-> 1138 oc = ObsCollection.from_waterinfo(
1139 extent=extent,
1140 file_or_dir=file_or_dir,
1141 name=name,
1142 ObsClass=ObsClass,
1143 locatie=locatie,
1144 grootheid_code=grootheid_code,
1145 groepering_code=groepering_code,
1146 parameter_code=parameter_code,
1147 proces_type=proces_type,
1148 tmin=tmin,
1149 tmax=tmax,
1150 only_metadata=only_metadata,
1151 keep_all_obs=keep_all_obs,
1152 epsg=epsg,
1153 progressbar=progressbar,
1154 location_gdf=location_gdf,
1155 **kwargs,
1156 )
1158 return oc
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/obs_collection.py:2840, in ObsCollection.from_waterinfo(cls, file_or_dir, extent, name, ObsClass, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax, only_metadata, keep_all_obs, epsg, progressbar, location_gdf, **kwargs)
2837 meta = {"name": name, "type": ObsClass}
2839 if (extent is not None) or (location_gdf is not None):
-> 2840 obs_list = waterinfo.get_obs_list_from_extent(
2841 extent,
2842 ObsClass,
2843 locatie=locatie,
2844 grootheid_code=grootheid_code,
2845 groepering_code=groepering_code,
2846 parameter_code=parameter_code,
2847 proces_type=proces_type,
2848 tmin=tmin,
2849 tmax=tmax,
2850 only_metadata=only_metadata,
2851 keep_all_obs=keep_all_obs,
2852 epsg=epsg,
2853 location_gdf=location_gdf,
2854 )
2855 elif file_or_dir is not None:
2856 obs_list = waterinfo.read_waterinfo_obs(
2857 file_or_dir, ObsClass, progressbar=progressbar, **kwargs
2858 )
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/io/waterinfo.py:100, in get_obs_list_from_extent(extent, ObsClass, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax, only_metadata, keep_all_obs, epsg, location_gdf)
98 o = ObsClass(meta=meta, **meta)
99 else:
--> 100 o = ObsClass.from_waterinfo(location_gdf=row, tmin=tmin, tmax=tmax)
101 if not keep_all_obs and o.empty:
102 continue
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/observation.py:1531, in WaterlvlObs.from_waterinfo(cls, path, location_gdf, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax, **kwargs)
1496 """Read data from waterinfo csv-file, zip or using the API.
1497
1498 Parameters
(...) 1527 if file contains data for more than one location
1528 """
1529 from .io import waterinfo
-> 1531 df, metadata = waterinfo.get_waterinfo_obs(
1532 path=path,
1533 location_gdf=location_gdf,
1534 locatie=locatie,
1535 grootheid_code=grootheid_code,
1536 groepering_code=groepering_code,
1537 parameter_code=parameter_code,
1538 proces_type=proces_type,
1539 tmin=tmin,
1540 tmax=tmax,
1541 **kwargs,
1542 )
1544 return cls(df, **metadata)
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/io/waterinfo.py:163, in get_waterinfo_obs(path, location_gdf, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax, **kwargs)
161 df, meta = read_waterinfo_file(path, **kwargs)
162 else:
--> 163 df, meta = get_measurements_ddlpy(
164 location_gdf,
165 locatie,
166 grootheid_code,
167 groepering_code,
168 parameter_code,
169 proces_type,
170 tmin,
171 tmax,
172 )
174 return df, meta
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/hydropandas/io/waterinfo.py:329, in get_measurements_ddlpy(location_gdf, locatie, grootheid_code, groepering_code, parameter_code, proces_type, tmin, tmax)
327 parameter_code = selected["Parameter.Code"]
328 proces_type = selected["ProcesType"]
--> 329 df = ddlpy.measurements(selected, start_date=tmin, end_date=tmax)
330 else:
331 selected = _select_location(
332 location_gdf,
333 locatie,
(...) 337 proces_type,
338 )
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/ddlpy/ddlpy.py:467, in measurements(location, start_date, end_date, freq, clean_df)
465 for start_date_i, end_date_i in date_series_iterator:
466 try:
--> 467 measurement = _measurements_slice(
468 location, start_date=start_date_i, end_date=end_date_i
469 )
470 measurements.append(measurement)
471 except NoDataError:
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/ddlpy/ddlpy.py:394, in _measurements_slice(location, start_date, end_date)
386 request_dicts = _get_request_dicts(location)
388 request = {
389 "AquoPlusWaarnemingMetadata": {"AquoMetadata": request_dicts["AquoMetadata"]},
390 "Locatie": request_dicts["Locatie"],
391 "Periode": {"Begindatumtijd": start_date_str, "Einddatumtijd": end_date_str},
392 }
--> 394 result = _send_post_request(endpoint["url"], request, timeout=None)
396 df = _combine_waarnemingenlijst(result, location)
397 return df
File ~/checkouts/readthedocs.org/user_builds/hydropandas/envs/latest/lib/python3.12/site-packages/ddlpy/ddlpy.py:38, in _send_post_request(url, request, timeout)
32 resp = requests.post(url, json=request, timeout=timeout)
34 if not resp.ok:
35 # in case of for instance
36 # resp.status_code: 400, resp.reason: Bad Request, resp.text: {"Succesvol":false,"Foutmelding":"Het maximaal aantal waarnemingen (160000) is overschreden. Beperk uw request.","WaarnemingenLijst":[]}
37 # resp.status_code: 500, resp.reason: Internal Server Error
---> 38 raise IOError(f"{resp.status_code} {resp.reason}: {resp.text}")
40 if resp.status_code == 204:
41 # "204 No Content" is raised here, but catched in ddlpy.ddlpy.measurements() so the process can continue.
42 raise NoDataError(f"{resp.status_code} {resp.reason}: {resp.text}")
OSError: 504 Gateway Timeout: Gateway Timeout
Retrieving data from WaterWebservices
In the future, the WaterWebservices will become available. Currently (2024-03-20), they are not yet working. When retrieving measurements, it is always indicated that the maximum number of measurements is exceeded. Even when retrieving measurements for only one day.
Useful information:
https://waterwebservices.beta.rijkswaterstaat.nl/test/swagger-ui/index.html#/
https://rijkswaterstaatdata.nl/projecten/beta-waterwebservices/
[13]:
# import json
# import requests
# from shapely.geometry import Point
# import nlmod
[14]:
# # request catalogus REST API
# url = "https://waterwebservices.beta.rijkswaterstaat.nl/test/METADATASERVICES/OphalenCatalogus"
# body = {"CatalogusFilter": {"Compartimenten": True, "Grootheden": True}}
# headers = {"content-type": "application/json"}
# r = requests.post(url, data=json.dumps(body), headers=headers)
# out = r.json()
[15]:
# # plot locations from REST API
# geometries = [Point(loc["Lon"], loc["Lat"]) for loc in out["LocatieLijst"]]
# gdf = gpd.GeoDataFrame(out["LocatieLijst"], geometry=geometries, crs=4258)
# gdf.to_crs(28992, inplace=True)
# # extent_nl_poly = nlmod.util.extent_to_polygon(
# [482.06, 306602.42, 284182.97, 637049.52]
# )
# gdf = gdf.loc[gdf.within(extent_nl_poly)]
# ax = gdf.plot(figsize=(10, 10))
# nlmod.plot.add_background_map(ax=ax)
[16]:
# read REST API using an extent (Schoonhoven zuid-west)
# extent_schoon = nlmod.util.polygon_from_extent((117850, 118180, 439550, 439900))
# gdf_schoon = gdf.loc[gdf.within(extent_schoon.buffer(10000))]
# ax = gdf_schoon.plot("Code", figsize=(10, 10), legend=True)
# nlmod.plot.add_background_map(ax=ax, alpha=0.5)
[17]:
# # kies code en laat zien welke parameters erbij horen
# code = "schoonhoven"
# df_meta_locatie = pd.DataFrame(out["AquoMetadataLocatieLijst"]).set_index(
# "Locatie_MessageID"
# )
# df_meta = pd.DataFrame(out["AquoMetadataLijst"])
# locatie_message_id = gdf.loc[gdf["Code"] == code, "Locatie_MessageID"].iloc[0]
# AquoMetaData_MessageIDs = df_meta_locatie.loc[
# locatie_message_id, "AquoMetaData_MessageID"
# ]
# if isinstance(AquoMetaData_MessageIDs, int):
# AquoMetaData_MessageIDs = [AquoMetaData_MessageIDs]
# df_meta.loc[AquoMetaData_MessageIDs]
[18]:
# # request om metingen op te halen
# code = "ameland.nes"
# aquometadata_message_id = 6
# url = "https://waterwebservices.beta.rijkswaterstaat.nl/test/ONLINEWAARNEMINGENSERVICES/OphalenWaarnemingen"
# body = {
# "Locatie": {"Code": code},
# "AquoPlusWaarnemingMetadata": {
# "AquoMetadata": {
# "Compartiment": {
# "Code": df_meta.loc[aquometadata_message_id, "Compartiment"]["Code"]
# },
# "Grootheid": {
# "Code": df_meta.loc[aquometadata_message_id, "Grootheid"]["Code"]
# },
# }
# },
# "Periode": {
# "Begindatumtijd": "2024-06-01T00:00:00.000+01:00",
# "Einddatumtijd": "2025-01-01T00:00:00.000+01:00",
# },
# }
# headers = {"content-type": "application/json"}
# r = requests.post(url, data=json.dumps(body), headers=headers)
# if r.status_code == 204:
# print("No data available")
# else:
# meas = r.json()
# print(meas)
[19]:
# # andere poging
# code = "ameland.nes"
# aquometadata_message_id = 6
# url = "https://waterwebservices.beta.rijkswaterstaat.nl/test/ONLINEWAARNEMINGENSERVICES/OphalenWaarnemingen"
# body = {
# "Locatie": {"Code": code},
# "AquoPlusWaarnemingMetadata": {
# "AquoMetadata": {
# "ProcesType": "verwachting",
# "Grootheid": {
# "Code": df_meta.loc[aquometadata_message_id, "Grootheid"]["Code"]
# },
# }
# },
# "Periode": {
# "Begindatumtijd": "2024-01-01T00:00:00.000+01:00",
# "Einddatumtijd": "2024-01-02T00:00:00.000+01:00",
# },
# }
# headers = {"content-type": "application/json"}
# r = requests.post(url, data=json.dumps(body), headers=headers)
# if r.status_code == 204:
# print("No data available")
# else:
# meas = r.json()
# print(meas)
[ ]: